



Polda 1 - parsování datového souboru #1
18. července 2022 - Hry
Zhruba před deseti lety jsem na fórum Poldy sháněl a rozjel diskuzi na téma soundtrack ze hry. Oficiálně žádný neexistuje, ale pokud mě paměť neklame, ozvala se na fóru osoba (JaneDutohlav?), která i později nahrála hudbu přímo ze hry. Deset let uplynulo a já se někdy v květnu pustil do analýzy datového souboru s nevalnými výsledky. Teprve nyní, o dva měsíce později, jsem přišel s většími průlomy!
Projekt jsem začal s konkrétním úmyslem, chtěl jsem kompletní a originální hudbu ze hry. Říkal jsem si, že při této příležitosti dostanu ze souboru co nejvíce dat včetně obrázků, animací a jiného. Než abych si nechal veškeré informace pro sebe, rozhodl jsem se zveřejnit co o souboru vím. Nic z datového souboru nechci použít komerčně a jde čistě o studijní účely. Chvála za vytvoření a kompletní autorská práva jdou lidem ze Zima Software a SleepTeam.
Hlavička souboru
První 31 byteů tvoří hlavička souboru:
0000:0000 | 53 6C 65 65 70 54 65 61 6D 20 28 63 29 20 72 65 | SleepTeam (c) re
0000:0010 | 73 6F 75 72 63 65 20 66 69 6C 65 2E 0A 0A 00 | source file....
Následují čtyři bytey, pro které nemám zařazení. První myšlenka byla, že se jedná o velikost souboru, ale nejedná. Číselné hodnoty mají pořadí bytů little-endian (nejméně významný byte je uložen na nejnižší adrese v paměti).
Zajímavé je, že hlavička se nachází v souboru hned třikrát. Jednou samozřejmě na začátku souboru a poté na offsetech 12D45D78 a 25AF3C80. Odpovídá to počtu dnů, během kterých se hra odehrává. Možná že byl plán rozdělit hru?
Data
Pokoušel jsem se soubor rozbít a nechat hru soubor načíst. Doufal jsem v užitečné chybové hlášky, které by mě mohly posunout vpřed. Většina se motala kolem výrazu resource number.
To mě později dovedlo ke zjištění, že skoro všechna data jsou prefixována skupinou byteů se složením RR RR 00 00 XX 03. Kde RR RR = resource number a XX = typ dat. Jsem si tímto prefixem velice jistý, ale stále mám jisté pochyby, jelikož u textů prefix chybí nebo se nachází jinde a mimo text obsahuje i pro mě neznámá data.
Za obrovské nakopnutí děkuji @gamiee, který dal pár tipů, jak binární soubory prozkoumávat.
Texty
Prozatimní odhad pro prefix textů je skupina byteů 00 00 E9 03. Texty samotné začínají na offsetu 02336E75 a skládají se ze čtyř byteů tvořící velikost řetězce a samotný řetězec.
V textu se používá speciální 7E byte, který v menu zvýrazňuje písmena. Možná i jinde, ale toto jsem prozatím nevyzkoušel. Pokud jde o diakritiku, tak je mapována dle neznámého klíče. Nejedná se o UTF8. Kupříkladu písmeno č je reprezentováno bytem 87, á bytem a0 a tak dále.
0x8f: b'\xc3\x81', # Á
0xa0: b'\xc3\xa1', # á
0x8b: b'\xc3\x8d', # Í
0xa1: b'\xc3\xad', # í
0x9b: b'\xc5\xa0', # Š
0xa8: b'\xc5\xa1', # š
0x80: b'\xc4\x8c', # Č
0x87: b'\xc4\x8d', # č
0x89: b'\xc4\x9a', # Ě
0x88: b'\xc4\x9b', # ě
0x90: b'\xc3\x89', # É
0x82: b'\xc3\xa9', # é
0x91: b'\xc5\xbe', # ž
0x92: b'\xc5\xbd', # Ž
0x9d: b'\xc3\x9d', # Ý
0x98: b'\xc3\xbd', # ý
0x9e: b'\xc5\x98', # Ř
0xa9: b'\xc5\x99', # ř
0x96: b'\xc5\xaf', # ů
0xa6: b'\xc5\xae', # Ů
0xa3: b'\xc3\x9a', # Ú
0x97: b'\xc3\xba', # ú
0x9f: b'\xc5\xa5', # ť
0x86: b'\xc5\xa4', # Ť
0xa5: b'\xc5\x87', # Ň
0xa4: b'\xc5\x87', # ň
0xa2: b'\xc3\xb3', # ó
0x94: b'\xc3\xb6', # ö
0x83: b'\xc4\x8f', # ď
0xa7: b'\xc2\xa7', # §
Zde je manuálně sestavená mapa znaků. Nemůžu vyloučit, že data před texty obsahují mapu znaků, ale tuto skutečnost jsem objevil před pár dny a neprozkoumal jsem jí více do hloubky. Hra byla vytvořena pro MS-DOS, takže ani nepočítám, že moje mapa bude odpovídat mapě v souboru. Spíš půjde o jiné kódování znaků.
Obrázky
Obrázky mají typ jako 00 00 EB 03. Všechny obrázky, které jsem doposud našel, tak jsou statické. Jde o pozadí scén, předměty a případné další předměty, které skládají celkovou scénu.
Formát hlavičky je poměrně jednoduchý. Celá hlavička zabírá 32 byteů (+ 2 byte pro resource number?). 00 00 EB 03 WW WW HH HH WW WW 00 00 HH HH 00 00 00 00 00 00 00 00 00 00 WW WW 00 00 HH HH 00 00
Proč je hlavička takto velká a několikrát se v ní opakuje šířka a výška v pixelech? Nemám nejmenší tušení, ale je to tak. Vytáhl jsem tímto způsobem přes 900 obrázků.
Samotná data obrázků jsou jen a pouze bytey jednotlivých pixelů v odstínu šedé.


Paleta barev
Naivně jsem se domníval o jednom druhu palety. Začal jsem ručně mapovat barvy na odstíny šedi. Díky tomu jsem přišel na existenci více palet, jelikož barvy použité u babičky v pokoji neodpovídají barvám, použitými v Pankrácově pokoji. Níže jsou nekompletní obrázky, u kterých používám růžovou barvu jako nezmapovanou barvu.


I tady jsem, a to opravdu obrovskou náhodou, učinil drobný pokrok, když jsem vzal kus náhodných dat a viděl toto.
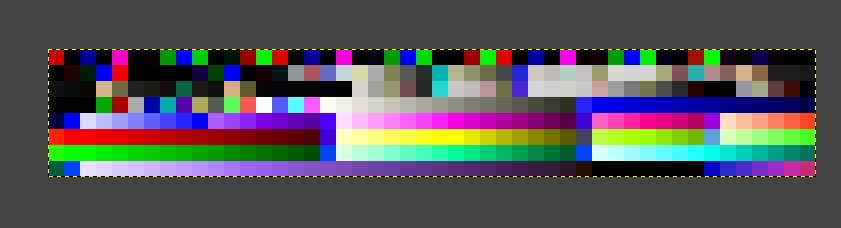
Stále by mohlo jít o čistě náhodu. Paletu samotnou jsem ještě nevyzkoušel na žádném obrázku a teprve mě to čeká. Můj odhad ovšem je že 00 00 FD 03, 00 00 F5 03 a 00 00 F6 03 jsou typy označující části palet a případně jejich mapování k obrázkům. Dost pravděpodobně podle resource number.
Hudba
Hudba byla můj první objev už před dvěma měsíci. V souboru se nachází 16 případů s textem Extended Module: FastTracker v 2.00 a typ je 00 00 FF 03. Jak je vidět, tak označení typu dat je napříč souborem dost konzistentní.
V první chvíli jsem nedokázal odhalit formát hudby. Vyhledával jsem chybně řetězec FastTracker, což byl hudební tracker. Když jsem se k hudbě ale později vrátil, dokázal jsem díky Extended Module najít, že se jedné o XM formát. O něm jsem našel více informací zde https://formats.kaitai.io/fasttracker_xm_module/index.html. Problém ovšem je, že formát nemá jednoduše definovanou velikost v bytech, ale v počtu patternů a instrumentů. Nedařilo se mi využít žádný skript k přesnému výpočtu byteů, které bych měl ze souboru vytáhnout. Zvolil jsem nakonec cestu hrubé síly.
S hudbou jsem stále ještě neskončil a chci určitě být schopný najít přesné hranice souborů. Hrubou silou jsem ovšem vzal velký kus souboru, který na 100% přesahoval data hudby, a prohnal ho přes Audacity. Audacity s tím nemělo nejmenší problém, nadbytečná data ignoroval a já měl 16 skladeb vyextrahovaných.
https://www.youtube.com/playlist?list=PLzBABaqpcROlsq5AuKTXDLVRPUg8SWDwc (díky za sestříhání @tigrik626)
Duplikace
S hudbou přišlo další osvícení, že spousta dat je duplikovaná. U obrázků jsem jev nepozoroval, ale stále jsem všech >900 obrázků neprošel. Hudba obsahuje 16 skladeb z čehož je pouze 8 unikátních. Zbytek jsou duplikáty. Tento fakt podporuje teorii, že datový soubor měl být rozdělen na více částí a možná tak i distribuované. Je to ale pouze odhad.
Závěr
Ohromná cesta je za mnou, ale možná ještě větší cesta je přede mnou. Ultimátní cíl analýzy je být schopen zmapovat datový soubor v jeho celé velikosti a identifikovat každý byte dat. Nevěnuji se tomu denně 8 hodin, takže nějaký měsíc mi práce ještě potrvá a snad se do té doby nevzdám.